{kind=link}
![[Tričko podporuji RFC 3023]](http://feedparser.org/img/feedparser.jpg)
Nacházíte se zde: Domů ‣ Ponořme se do Pythonu 3 ‣
Úroveň obtížnosti: ♦♦♦♦♢
❝ A ruffled mind makes a restless pillow. ❞
(Rozbouřená mysl je nepohodlný polštář.)
— Charlotte Bronteová
Z filozofického hlediska můžeme webové služby nad HTTP (HyperText Transfer Protocol) popsat devíti slovy: výměna dat se vzdálenými servery pouze s použitím operací protokolu HTTP. Pokud chceme ze serveru získat data, použijeme HTTP GET. Pokud chceme nová data na server zaslat, použijeme HTTP POST. Některá pokročilejší aplikační rozhraní (API) webových služeb nad HTTP umožňují také vytváření, modifikaci a rušení dat použitím HTTP PUT a HTTP DELETE. To je vše. Žádné registry, žádné obálky, žádný obalující kód, žádné tunelování. „Slovesa“, která jsou součástí HTTP protokolu (GET, POST, PUT a DELETE) přímo odpovídají operacím na aplikační úrovni pro získávání, vytváření, modifikaci a rušení dat.
Hlavní výhodou tohoto přístupu je jednoduchost a právě jednoduchost vedla k jeho oblibě. Data — obvykle XML nebo JSON — mohou být vytvořena a uložena jako statická, nebo mohou být generována dynamicky, skriptem na straně serveru. Všechny hlavní programovací jazyky (samozřejmě včetně Pythonu) umožňují stahování těchto dat prostřednictvím svých HTTP-knihoven. Jednodušší je i ladění. Každý prostředek (resource) webové služby nad HTTP má jednoznačnou adresu v podobě URL. Po zadání do webového prohlížeče dojde k načtení a hned vidíte surová data.
Příklady webových služeb nad HTTP:
Pro interakci s webovými službami nad HTTP jsou v Pythonu 3 k dispozici dvě různé knihovny:
http.client je nízkoúrovňová knihovna, která implementuje RFC 2616, tedy HTTP-protokol.
urllib.request je knihovna na vyšší úrovni abstrakce, vybudovaná nad http.client. Poskytuje standardní aplikační rozhraní pro zpřístupňování jak HTTP, tak FTP serverů, automaticky následuje přesměrování HTTP a podporuje některé běžné formy autentizace v HTTP.
Takže který mám použít? Z těchto dvou žádný. Místo toho byste měli použít httplib2, což je open source knihovna třetí strany, která implementuje HTTP do větších detailů než http.client. Současně používá lepší abstrakce než urllib.request.
Abyste porozuměli tomu, proč je httplib2 tou správnou volbou, musíte nejdříve porozumět HTTP.
⁂
Každý HTTP klient by měl podporovat pět důležitých vlastností.
Nejdůležitější věcí, které musíme v souvislosti s libovolným typem webové služby rozumět, je to, že přístup k síti je velmi drahý. Nemám na mysli cenu „v penězích“ (i když šířka přenosového pásma není zadarmo). Mám na mysli to, že hrozně dlouhou dobu zabere otevření spojení, odeslání požadavku a získání odezvy ze vzdáleného serveru. Dokonce i v případě nejrychlejšího dostupného spojení může být latence (tj. čas mezi zasláním požadavku a zahájením přijímání dat odpovědi) vyšší, než byste předpokládali. Směrovače mohou zafungovat divně, paket se ztratí, na mezilehlý server někdo zaútočil... Na veřejné internetové síti není nikdy klidná chvilka a nic s tím nenaděláte.
Při návrhu HTTP se počítalo s využíváním mezipaměti (cache). Existuje dokonce samostatná třída zařízení (zvaných „mezipaměťové proxy-servery“, anglicky „chaching proxies“), jejichž jedinou prací je ležet mezi vámi a zbytkem světa a minimalizovat zatěžování sítě. Vaše firma nebo váš poskytovatel připojení (ISP) téměř jistě mezipaměťové proxy-servery udržuje, i když si toho nemusíte být vědomi. Fungují, protože používání mezipaměti (caching) je součástí HTTP protokolu.
Následuje konkrétní příklad toho, jak to funguje. Prostřednictvím svého prohlížeče navštívíte diveintomark.org. Uvedená stránka používá pro pozadí obrázek wearehugh.com/m.jpg. Když váš prohlížeč obrázek stáhne, server k němu přiloží následující HTTP hlavičky:
HTTP/1.1 200 OK
Date: Sun, 31 May 2009 17:14:04 GMT
Server: Apache
Last-Modified: Fri, 22 Aug 2008 04:28:16 GMT
ETag: "3075-ddc8d800"
Accept-Ranges: bytes
Content-Length: 12405
Cache-Control: max-age=31536000, public
Expires: Mon, 31 May 2010 17:14:04 GMT
Connection: close
Content-Type: image/jpegHlavičky Cache-Control a Expires říkají vašemu prohlížeči (a všem mezipaměťovým proxy-serverům mezi vámi a serverem), že se tento obrázek může získávat z mezipaměti až jeden rok. Celý rok! A pokud někdy v příštím roce navštívíte jinou stránku, která také obsahuje odkaz na tento obrázek, váš prohlížeč jej načte ze své mezipaměti, aniž by vyvolal jakoukoliv síťovou aktivitu.
Ale počkejte, bude to ještě lepší. Dejme tomu, že váš prohlížeč obrázek z lokální mezipaměti z nějakého důvodu odstraní. Možná mu došlo místo na disku, možná jste mezipaměť vyprázdnili ručně. Z jakéhokoliv důvodu. Ale HTTP hlavičky říkají, že tato data mohou být uchovávána veřejnými mezipaměťovými proxy-servery. (Z technického pohledu je důležité, co hlavičky neříkají. Hlavička Cache-Control neuvádí klíčové slovo private, takže data mohou být uložena v mezipaměti automaticky.) Mezipaměťové proxy-servery jsou navrženy tak, že mají k dispozici obrovské množství úložného prostoru — pravděpodobně ho mají mnohem více, než má vyhrazeno váš lokální prohlížeč.
Pokud vaše firma nebo váš poskytovatel připojení spravuje mezipaměťový proxy-server, může se v jeho mezipaměti obrázek pořád ještě nacházet. Pokud navštívíte diveintomark.org znovu, podívá se váš prohlížeč po obrázku do lokální mezipaměti, ale nenajde jej. Takže vytvoří síťový požadavek a pokusí se obrázek stáhnout ze vzdáleného serveru. Pokud ale mezipaměťový proxy-server pořád má kopii uvedeného obrázku, váš požadavek zachytí a dodá vám obrázek ze své mezipaměti. To znamená, že se váš požadavek ke vzdálenému serveru nikdy nedostane. Ve skutečnosti nemusí opustit vaši firemní síť. Získání obrázku je rychlejší (méně skoků po síti) a vaše firma ušetří peníze (z vnějšího světa se stahuje méně dat).
Použití mezipamětí v HTTP funguje, pokud všechny strany dělají, co mají. Na jedné straně musí servery v odpovědích posílat správné hlavičky. Na druhé straně musí klienti hlavičkám rozumět, respektovat je a nežádat stejná data dvakrát. Mezilehlé proxy-servery nejsou všelékem. Mohou být „chytré“ jen do té míry, do jaké jim to servery a klienti umožní.
Standardní pythonovské knihovny pro HTTP používání mezipaměti nepodporují, ale httplib2 ano.
Některá data se nemění nikdy, zatímco jiná data se mění pořád. A mezi tím je obrovské množství dat, která se mohla změnit, ale nezměnila se. Publikovaný obsah (feed) serveru CNN.com se mění každých pár minut, ale publikovaný obsah mého weblogu se nemusí změnit celé dny nebo týdny. I kdyby to byl ten druhý případ, nechci klientům říct, aby si můj publikovaný obsah brali z mezipaměti celé týdny, protože pokud bych doopravdy něco nového zveřejnil, lidé by se o tom celé týdny nedozvěděli (protože by respektovali mé hlavičky týkající se mezipaměti, které říkají „neobtěžujte se s kontrolou tohoto publikovaného obsahu po celé týdny“). Na druhou stranu zase nechci, aby klienti stahovali celý publikovaný obsah (feed) každou hodinu, pokud se vůbec nezměnil!
HTTP nabízí řešení i pro tento případ. Pokud o data žádáme poprvé, server může zpět poslat hlavičku Last-Modified (naposledy změněno). Je to přesně to, jak to vypadá: datum a čas, kdy se data naposledy změnila. Obrázek pozadí, na který vedl odkaz z diveintomark.org, doprovázela hlavička Last-Modified.
HTTP/1.1 200 OK
Date: Sun, 31 May 2009 17:14:04 GMT
Server: Apache
Last-Modified: Fri, 22 Aug 2008 04:28:16 GMT
ETag: "3075-ddc8d800"
Accept-Ranges: bytes
Content-Length: 12405
Cache-Control: max-age=31536000, public
Expires: Mon, 31 May 2010 17:14:04 GMT
Connection: close
Content-Type: image/jpeg
Pokud požadujeme stejná data podruhé (nebo potřetí nebo počtvrté), můžeme v dotazu poslat hlavičku If-Modified-Since (pokud bylo změněno od) s hodnotou data a času, které jsme od serveru dostali minule. Pokud se data od té doby změnila, pak server vrátí nová data doplněná o stavový kód 200. Ale pokud se data od té doby nezměnila, server pošle zpět speciální stavový kód protokolu HTTP — 304. Ten říká „od doby, kdy ses naposledy ptal, se tato data nezměnila“. Z příkazového řádku si to můžeme ověřit nástrojem curl:
you@localhost:~$ curl -I -H "If-Modified-Since: Fri, 22 Aug 2008 04:28:16 GMT" http://wearehugh.com/m.jpg HTTP/1.1 304 Not Modified Date: Sun, 31 May 2009 18:04:39 GMT Server: Apache Connection: close ETag: "3075-ddc8d800" Expires: Mon, 31 May 2010 18:04:39 GMT Cache-Control: max-age=31536000, public
A proč by to mělo být vylepšení? Protože když server pošle 304, neposílá data znovu. Dostaneme pouze stavový kód. Kontrola poslední modifikace zajistí, že se nezměněná data nebudou stahovat podruhé i v případě, kdy došlo k vypršení platnosti kopie v lokální mezipaměti. (Jako bonus navíc obsahuje odpověď 304 také hlavičky pro mezipaměť. Proxy-servery si kopii dat drží, dokonce i když oficiálně „expirovala“, v naději, že se data ve skutečnosti nezměnila a že další požadavek povede k odpovědi se stavovým kódem 304 a s aktualizovanými informacemi pro mezipaměť.)
Standardní pythonovské knihovny pro HTTP nepodporují kontrolu data poslední modifikace, ale httplib2 ano.
ETagy (tag = značka) představují alternativní způsob dosažení stejného efektu jako v případě kontroly last-modified. Při použití ETagů posílá server spolu s požadovanými daty v hlavičce ETag s heš-kódem (hash). (Jak se přesně heš-hodnota určí, to závisí zcela na serveru. Jediný požadavek je takový, aby se změnila, pokud se změní data.) Obrázek pozadí, na který vedl odkaz z diveintomark.org, doprovázela hlavička ETag.
HTTP/1.1 200 OK
Date: Sun, 31 May 2009 17:14:04 GMT
Server: Apache
Last-Modified: Fri, 22 Aug 2008 04:28:16 GMT
ETag: "3075-ddc8d800"
Accept-Ranges: bytes
Content-Length: 12405
Cache-Control: max-age=31536000, public
Expires: Mon, 31 May 2010 17:14:04 GMT
Connection: close
Content-Type: image/jpeg
Pokud stejná data požadujeme podruhé, přiložíme heš-hodnotu v hlavičce pořadavku If-None-Match (pokud žádná data neodpovídají). Pokud se data nezměnila, server pošle zpět stavový kód 304. Server — stejně jako v případě kontroly založené na čase poslední modifikace — pošle zpět pouze stavový kód 304. Stejná data znovu neposílá. Přiložením heš-hodnoty v ETagu při druhém požadavku serveru říkáme, že při shodě heše není nutné posílat stejná data znovu, protože je pořád máme schovaná od minula.
Opět vyzkoušíme pomocí curl:
you@localhost:~$ curl -I -H "If-None-Match: \"3075-ddc8d800\"" http://wearehugh.com/m.jpg ①
HTTP/1.1 304 Not Modified
Date: Sun, 31 May 2009 18:04:39 GMT
Server: Apache
Connection: close
ETag: "3075-ddc8d800"
Expires: Mon, 31 May 2010 18:04:39 GMT
Cache-Control: max-age=31536000, public
If-None-Match musíme serveru poslat zpět i uvozovky.
Standardní pythonovské knihovny pro HTTP používání ETagů nepodporují, ale httplib2 ano.
Pokud se bavíme o webových službách nad HTTP, pak se téměř vždy bavíme o přesunování textových dat po drátech tam a zase zpět. Možná jsou ve formátu XML, možná jsou v JSON, možná je to prostý text. Text se dá dobře komprimovat nezávisle na použitém formátu. Příklad publikovaného obsahu (feed) z kapitoly XML má nekomprimovaný 3070 bajtů, ale po kompresi algoritmem gzip má 941 bajtů. To je jen 30 % původní velikosti!
HTTP podporuje několik komprimačních algoritmů. Mezi dva nejběžnější patří gzip a deflate. Pokud přes HTTP požadujeme nějaký prostředek (resource), můžeme serveru říci, aby ho poslal v komprimovaném formátu. Do požadavku vložíme hlavičku Accept-encoding, ve které vyjmenujeme námi podporované komprimační algoritmy. Pokud server některý z těchto algoritmů podporuje, pošle nám zpět komprimovaná data (s hlavičkou Content-encoding, která říká, jaký algoritmus byl použit). O dekompresi se už musíme postarat sami.
☞Důležitý tip pro vývojáře kódu na straně serveru: Ujistěte se, že komprimovaná podoba zdroje dostane přidělenou jinou značku Etag než nekomprimovaná verze. V opačném případě by došlo ke zmatení mezipaměťových proxy-serverů a ty by mohly klientům vracet komprimovanou verzi, se kterou by si klient nemusel poradit. Více detailů o této delikátní záležitosti si můžete přečíst v diskusi Apache bug 39727.
Standardní pythonovské knihovny pro HTTP kompresi nepodporují, ale httplib2 ano.
Senzační URI se nemění, ale mnohá URI jsou opravdu… nesenzační. Webová místa se reorganizují, stránky se přesouvají na nové adresy. Dokonce i webové služby mohou být reorganizovány. Publikovaný obsah (syndicated feed) mohl být přesunut z http://example.com/index.xml do http://example.com/xml/atom.xml. Nebo se při rozšiřování a reorganizaci firmy mohla přesunout celá doména. Z http://www.example.com/index.xml se mění na http://server-farm-1.example.com/index.xml.
Pokaždé, když HTTP server požádáme o nějaký zdroj (resource), vrací v odpovědi stavový kód. Stavový kód 200 znamená „vše v pořádku, tady je požadovaná stránka“. Stavový kód 404 znamená „stránka nenalezena“. (Chybu 404 jste už asi při brouzdání po webu viděli.) Stavové kódy ve skupině 300 vyjadřují nějakou formu přesměrování.
HTTP nabízí několik způsobů, jakými se dá oznámit, že se požadované zdroje přesunuly. Dvě nejběžnější techniky používají stavové kódy 302 a 301. Stavový kód 302 označuje dočasné přesměrování. Znamená „ejhle, je to dočasně přesunuté“ (a v hlavičce Location se vrátí dočasná adresa). Stavový kód 301 označuje trvalé přesměrování. Znamená „ejhle, je to trvale přesunuté“ (a v hlavičce Location se vrací nová adresa). Pokud obdržíte stavový kód 302 a novou adresu, pak máte podle specifikace HTTP pro požadovanou věc použít novou adresu. Ale až se budete na stejný zdroj informací ptát příště, máte to znovu zkusit s původní adresou. Pokud ale obdržíte stavový kód 301 a k němu novou adresu, očekává se od vás, že od toho okamžiku začnete používat novou adresu.
Modul urllib.request při obdržení příslušného stavového kódu od HTTP serveru sice „následuje“ přesměrování, ale neřekne vám, že tato situace nastala. Dostanete data, která jste požadovali, ale nikdy se nedozvíte, že se použitá knihovna zachovala „užitečně“ a následovala přesměrování za vás. Takže pořád bušíte na staré adrese a pokaždé jste serverem přesměrováni na novou adresu a modul urllib.request pokaždé „užitečně“ následuje přesměrování. Jinými slovy, tato knihovna se k trvalému přesměrování chová stejně jako k dočasnému přesměrování. To znamená, že se místo jednoho kola provedou vždycky dvě. To je špatné jak pro server, tak pro vás.
Knihovna httplib2 trvalé přesměrování zvládá. Nejen že vám řekne, že nastalo trvalé přesměrování, ale lokálně si je poznamená a přesměrovaná URL automaticky přepíše dříve, než vznese příslušný požadavek.
⁂
Dejme tomu, že přes HTTP chceme stáhnout informační zdroj, jako je například Atom feed. Protože jde o publikovaný obsah (feed), nebudeme jej stahovat jen jednou. Budeme jej stahovat opakovaně, pořád dokola. (Většina čteček publikovaného obsahu (feed reader) kontroluje změny každou hodinu.) Nejdříve vyzkoušíme „rychlý a špinavý“ způsob a pak se podíváme, jak bychom to mohli provádět lépe.
>>> import urllib.request >>> a_url = 'http://diveintopython3.org/examples/feed.xml' >>> data = urllib.request.urlopen(a_url).read() ① >>> type(data) ② <class 'bytes'> >>> print(data) <?xml version='1.0' encoding='utf-8'?> <feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'> <title>dive into mark</title> <subtitle>currently between addictions</subtitle> <id>tag:diveintomark.org,2001-07-29:/</id> <updated>2009-03-27T21:56:07Z</updated> <link rel='alternate' type='text/html' href='http://diveintomark.org/'/> …
urllib.request nabízí šikovnou funkci urlopen(), která přebírá adresu požadované stránky a vrací objekt typu stream, ze kterého získáme celý obsah stránky prostým zavoláním metody read(). Už to asi nemůže být jednodušší.
urlopen().read() vrací vždy objekt typu bytes a ne řetězec. Vzpomeňte si — bajty jsou bajty, znaky jsou abstrakce. HTTP servery nepracují s abstrakcemi. Kdykoliv požádáme o nějaký zdroj (resource), dostaneme bajty. Pokud z toho chceme udělat řetězec, musíme zjistit znakové kódování a provést explicitní převod na řetězec.
A co na tom je špatného? Při rychlém, jednorázovém přístupu během ladění a vývoje na tom není špatného nic. Dělám to takhle pořád. Chtěl jsem publikovaný obsah (feed), dostal jsem publikovaný obsah. Stejná technika funguje pro libovolné webové stránky. Ale jakmile o tom začneme uvažovat z pohledu webové služby, která se má využívat pravidelně (tj. požadavek na získání publikovaného obsahu každou hodinu), pak by to bylo neefektivní a my bychom byli nezdvořilí.
⁂
Abychom viděli, proč je to neefektivní a nezdvořilé, obrátíme se na ladicí prostředky pythonovské knihovny pro HTTP a uvidíme, co běhá „po drátech“ (tj. co se přenáší v síti).
>>> from http.client import HTTPConnection >>> HTTPConnection.debuglevel = 1 ① >>> from urllib.request import urlopen >>> response = urlopen('http://diveintopython3.org/examples/feed.xml') ② send: b'GET /examples/feed.xml HTTP/1.1 ③ Host: diveintopython3.org ④ Accept-Encoding: identity ⑤ User-Agent: Python-urllib/3.1' ⑥ Connection: close reply: 'HTTP/1.1 200 OK' …further debugging information omitted…
urllib.request spoléhá na další standardní pythonovskou knihovnu, http.client. S knihovnou http.client za normálních okolností do přímého styku nepřicházíte. (Modul urllib.request ji importuje automaticky.) Ale my si ji importujeme ručně, abychom mohli nastavit příznak ladění u třídy HTTPConnection, kterou modul urllib.request používá pro připojení k HTTP serveru.
urllib.request posílá serveru pět řádků.
GET) a cestu ke zdroji (bez uvedení jména domény).
urllib.request standardně kompresi nepodporuje.
Python-urllib a číslo verze. Jak urllib.request, tak httplib2 podporují změnu identifikace zprostředkovatele tím, že se do požadavku jednoduše přidá hlavička User-Agent, která přepíše výchozí hodnotu.
Teď se podívejme na to, jakou odpověď poslal server zpět.
# pokračování předchozího příkladu >>> print(response.headers.as_string()) ① Date: Sun, 31 May 2009 19:23:06 GMT ② Server: Apache Last-Modified: Sun, 31 May 2009 06:39:55 GMT ③ ETag: "bfe-93d9c4c0" ④ Accept-Ranges: bytes Content-Length: 3070 ⑤ Cache-Control: max-age=86400 ⑥ Expires: Mon, 01 Jun 2009 19:23:06 GMT Vary: Accept-Encoding Connection: close Content-Type: application/xml >>> data = response.read() ⑦ >>> len(data) 3070
urllib.request.urlopen() obsahuje všechny HTTP hlavičky, které server poslal zpět. Obsahuje také metody pro stahování skutečných dat. K tomu se dostaneme za minutku.
Last-Modified.
ETag.
Content-encoding. V požadavku jsme uvedli, že přijímáme jen nekomprimovaná data (Accept-encoding: identity), takže jsme tím pádem dostali nekomprimovaná data.
response.read(). Z výsledku funkce len() vidíme, že se stáhlo všech 3070 bajtů najednou.
Jak sami vidíte, tento kód je už teď neefektivní. Požadoval (a obdržel) nekomprimovaná data. Určitě vím, že uvedený server podporuje kompresi gzip, ale v HTTP se komprese zapíná na vyžádání. Nepožádali jsme o ni, tak jsme ji nedostali. To znamená, že jsme stahovali 3070 bajtů v situaci, kdy jsme mohli stahovat pouhých 941. Zlobivý pejsek, žádná sušenka.
Ale moment, začíná to být ještě horší! Abychom viděli, jak neefektivní ten kód je, požádáme o stejný publikovaný obsah (feed) podruhé.
# pokračování předchozího příkladu
>>> response2 = urlopen('http://diveintopython3.org/examples/feed.xml')
send: b'GET /examples/feed.xml HTTP/1.1
Host: diveintopython3.org
Accept-Encoding: identity
User-Agent: Python-urllib/3.1'
Connection: close
reply: 'HTTP/1.1 200 OK'
…further debugging information omitted…
Všimli jste si na tom požadavku něčeho zvláštního? Vůbec se nezměnil! Je naprosto stejný jako ten předchozí. Žádná známka použití hlavičky If-Modified-Since. Žádná známka použití hlavičky If-None-Match. Žádný respekt k hlavičkám mezipaměti. Ještě pořád žádná komprese.
A co se stane, když uděláme stejnou věc dvakrát? Dostaneme stejnou odpověď. Dvakrát.
# pokračování předchozího příkladu >>> print(response2.headers.as_string()) ① Date: Mon, 01 Jun 2009 03:58:00 GMT Server: Apache Last-Modified: Sun, 31 May 2009 22:51:11 GMT ETag: "bfe-255ef5c0" Accept-Ranges: bytes Content-Length: 3070 Cache-Control: max-age=86400 Expires: Tue, 02 Jun 2009 03:58:00 GMT Vary: Accept-Encoding Connection: close Content-Type: application/xml >>> data2 = response2.read() >>> len(data2) ② 3070 >>> data2 == data ③ True
Cache-Control a Expires pro mezipaměť (cache), Last-Modified a ETag pro sledování „nezměněného stavu“. A dokonce hlavičku Vary: Accept-Encoding, kterou server dává najevo, že by mohl podporovat kompresi, kdybychom si o ni řekli. Ale my jsme to neudělali.
Protokol HTTP je navržen, aby pracoval lepším způsobem. Knihovna urllib umí HTTP asi tak, jak já umím španělsky — dost na to, abych se dostal z problémů, ale ne dost k vedení konverzace. A HTTP se týká konverzace. Je čas přejít ke knihovně, která protokolem HTTP mluví plynule.
⁂
httplib2Než začneme knihovnu httplib2 používat, musíme ji nainstalovat. Navštivte stránku code.google.com/p/httplib2/ a stáhněte poslední verzi. httplib2 je k dispozici pro Python 2.x a pro Python 3.x. Ujistěte se, že jde o verzi pro Python 3. Jmenuje se podobně jako httplib2-python3-0.5.0.zip. (V době překladu už to bylo jinak: httplib2-0.6.0.zip; uvnitř jsou obě verze.)
Rozbalte archiv, otevřete terminálové okno a přejděte do nově vytvořeného adresáře httplib2. Pod Windows otevřete menu Start, vyberte Run..., napište cmd.exe a stiskněte ENTER.
c:\Users\pilgrim\Downloads> dir
Volume in drive C has no label.
Volume Serial Number is DED5-B4F8
Directory of c:\Users\pilgrim\Downloads
07/28/2009 12:36 PM <DIR> .
07/28/2009 12:36 PM <DIR> ..
07/28/2009 12:36 PM <DIR> httplib2-python3-0.5.0
07/28/2009 12:33 PM 18,997 httplib2-python3-0.5.0.zip
1 File(s) 18,997 bytes
3 Dir(s) 61,496,684,544 bytes free
c:\Users\pilgrim\Downloads> cd httplib2-python3-0.5.0
c:\Users\pilgrim\Downloads\httplib2-python3-0.5.0> c:\python31\python.exe setup.py install
running install
running build
running build_py
running install_lib
creating c:\python31\Lib\site-packages\httplib2
copying build\lib\httplib2\iri2uri.py -> c:\python31\Lib\site-packages\httplib2
copying build\lib\httplib2\__init__.py -> c:\python31\Lib\site-packages\httplib2
byte-compiling c:\python31\Lib\site-packages\httplib2\iri2uri.py to iri2uri.pyc
byte-compiling c:\python31\Lib\site-packages\httplib2\__init__.py to __init__.pyc
running install_egg_info
Writing c:\python31\Lib\site-packages\httplib2-python3_0.5.0-py3.1.egg-info
V Mac OS X spusťte aplikaci Terminal.app, kterou najdete ve složce /Applications/Utilities/. V Linuxu spusťte aplikaci Terminal, kterou obvykle najdete v menu Applications pod Accessories nebo System.
you@localhost:~/Desktop$ unzip httplib2-python3-0.5.0.zip Archive: httplib2-python3-0.5.0.zip inflating: httplib2-python3-0.5.0/README inflating: httplib2-python3-0.5.0/setup.py inflating: httplib2-python3-0.5.0/PKG-INFO inflating: httplib2-python3-0.5.0/httplib2/__init__.py inflating: httplib2-python3-0.5.0/httplib2/iri2uri.py you@localhost:~/Desktop$ cd httplib2-python3-0.5.0/ you@localhost:~/Desktop/httplib2-python3-0.5.0$ sudo python3 setup.py install running install running build running build_py creating build creating build/lib.linux-x86_64-3.1 creating build/lib.linux-x86_64-3.1/httplib2 copying httplib2/iri2uri.py -> build/lib.linux-x86_64-3.1/httplib2 copying httplib2/__init__.py -> build/lib.linux-x86_64-3.1/httplib2 running install_lib creating /usr/local/lib/python3.1/dist-packages/httplib2 copying build/lib.linux-x86_64-3.1/httplib2/iri2uri.py -> /usr/local/lib/python3.1/dist-packages/httplib2 copying build/lib.linux-x86_64-3.1/httplib2/__init__.py -> /usr/local/lib/python3.1/dist-packages/httplib2 byte-compiling /usr/local/lib/python3.1/dist-packages/httplib2/iri2uri.py to iri2uri.pyc byte-compiling /usr/local/lib/python3.1/dist-packages/httplib2/__init__.py to __init__.pyc running install_egg_info Writing /usr/local/lib/python3.1/dist-packages/httplib2-python3_0.5.0.egg-info
Abychom mohli httplib2 používat, vytvoříme instanci třídy httplib2.Http.
>>> import httplib2
>>> h = httplib2.Http('.cache') ①
>>> response, content = h.request('http://diveintopython3.org/examples/feed.xml') ②
>>> response.status ③
200
>>> content[:52] ④
b"<?xml version='1.0' encoding='utf-8'?>\r\n<feed xmlns="
>>> len(content)
3070
httplib2 je objekt třídy Http. Z důvodů, které si ukážeme v další podkapitole, bychom při vytváření objektu třídy Http měli vždy předávat jméno adresáře. Adresář nemusí existovat. V případě potřeby si jej httplib2 vytvoří.
Http k dispozici, můžeme data získat jednoduše tím, že zavoláme metodu request() a předáme jí adresu dat. Pro dané URL se tím vytvoří požadavek HTTP GET. (Později v této kapitole si ukážeme, jak můžeme vytvořit jiné HTTP požadavky, jako například POST.)
request() vrací dvě hodnoty. První hodnotou je objekt třídy httplib2.Response, který obsahuje všechny HTTP hlavičky vrácené serverem. Například hodnota stavového kódu (status) 200 indikuje, že byl dotaz proveden úspěšně.
bytes, nikoliv jako řetězec. Pokud z toho chceme udělat řetězec, musíme zjistit znakové kódování a převést si je sami.
☞Pravděpodobně budete potřebovat jen jeden objekt třídy
httplib2.Http. Existují rozumné důvody pro vytváření více než jednoho objektu, ale měli byste to dělat jen v případě, kdy víte, proč je potřebujete. „Potřebuji získávat data ze dvou různých URL“ takovým důvodem není. Použijte objekt třídyHttpznovu — prostě zavolejte metodurequest()dvakrát.
httplib2 vrací bajty místo řetězcůBajty. Řetězce. To je bolest. Proč httplib2 nemůže „jednoduše“ provést konverzi za nás? No, ono je to komplikované, protože pravidla pro zjištění znakového kódování jsou specifická v závislosti na tom, jaký zdroj (resource) požadujeme. Jak by mohla httplib2 vědět, jaký druh zdroje požadujeme? Obvykle bývá uveden v HTTP hlavičce Content-Type, ale tato hlavička je v HTTP nepovinná a ne všechny HTTP servery ji vkládají. Pokud tato hlavička není součástí HTTP odpovědi, ponechává se odhad na klientovi. (Říká se tomu anglicky „content sniffing“ čili „čmuchání v obsahu“. Výsledek není nikdy perfektní.)
Pokud víme, jaký druh dat očekáváme (v našem případě XML dokument), mohli bychom „jednoduše“ předat objekt typu bytes funkci xml.etree.ElementTree.parse(). To by fungovalo, kdyby XML dokument obsahoval informaci o svém vlastním kódování znaků (jako je tomu v tomto případě). Ale jde o nepovinný údaj a ne všechny XML dokumenty ho používají. Pokud XML dokument informaci o kódování neobsahuje, měl by se klient podívat na transportní obálku — tj. na HTTP hlavičku Content-Type, která by mohla parametr charset obsahovat.
Ale ono je to ještě horší. Teď už může být informace o kódování uvedena na dvou místech: uvnitř samotného XMLdokumentu a uvnitř HTTP hlavičky Content-Type. Jenže když je tato informace uvedena na obou místech, které z nich vyhraje? Podle RFC 3023 platí (a přísahám, to jsem si nevymyslel): pokud je v HTTP hlavičce Content-Type uveden typ média application/xml, application/xml-dtd, application/xml-external-parsed-entity nebo libovolný z podtypů application/xml, jako je application/atom+xml nebo application/rss+xml nebo dokonce application/rdf+xml, pak je kódování rovno
charset v HTTP hlavičce Content-Type nebo
encoding v XML deklaraci uvnitř dokumentu nebo
Na druhou stranu, pokud je v HTTP hlavičce Content-Type uveden typ média text/xml, text/xml-external-parsed-entity nebo podtyp jako text/AnythingAtAll+xml, pak se atribut uvádějící kódování v XML deklaraci uvnitř dokumentu zcela ignoruje a kódování je rovno
Content-Type nebo
us-ascii
A to se bavíme jen o XML dokumentech. Pro HTML dokumenty vytvořily webové prohlížeče taková byzantská pravidla pro zjišťování obsahu (content-sniffing) [PDF], že se stále ještě snažíme všechna zjistit.
httplib2 zachází s mezipamětíVzpomínáte si, že jsem vás v předchozí podkapitole nabádal, abyste vždy vytvářeli objekt třídy httplib2.Http se zadaným jménem adresáře? Důvod se jmenuje mezipaměť (cache).
# pokračování z předchozího příkladu
>>> response2, content2 = h.request('http://diveintopython3.org/examples/feed.xml') ①
>>> response2.status ②
200
>>> content2[:52] ③
b"<?xml version='1.0' encoding='utf-8'?>\r\n<feed xmlns="
>>> len(content2)
3070
status) 200, jako minule.
Takže… koho to zajímá? Ukončete pythonovský interaktivní shell a spusťte nové sezení. Hned vám to ukážu.
# toto NENÍ pokračování z předchozího příkladu! # Ukončete, prosím, interaktivní shell # a spusťte nový. >>> import httplib2 >>> httplib2.debuglevel = 1 ① >>> h = httplib2.Http('.cache') ② >>> response, content = h.request('http://diveintopython3.org/examples/feed.xml') ③ >>> len(content) ④ 3070 >>> response.status ⑤ 200 >>> response.fromcache ⑥ True
httplib2 zapíná ladicí režim (srovnejte se zapínáním v http.client). httplib2 vytiskne všechna data, která se posílají na server, a některé klíčové informace, které se posílají zpět.
httplib2.Http se stejným jménem adresáře jako minule.
httplib2. Adresář, jehož jméno jsme zadávali při vytváření objektu třídy httplib2.Http, slouží knihovně httplib2 jako mezipaměť (cache) pro všechny operace, které se kdy provedly.
☞Pokud chcete v
httplib2zapnout ladicí režim, musíte nastavit konstantu na úrovni modulu (httplib2.debuglevel) a potom vytvořit nový objekt třídyhttplib2.Http. Pokud chcete ladicí režim vypnout, musíte změnit tutéž konstantu na úrovni modulu a potom vytvořit nový objekt třídyhttplib2.Http.
Minule jsme požadovali data z konkrétního URL. Požadavek byl úspěšný (status: 200). Odpověď zahrnovala nejen data publikovaného obsahu, ale také množinu hlaviček pro mezipaměť (caching headers). Ty každému příjemci říkají, že si tento zdroj může pamatovat po dobu až 24 hodin (Cache-Control: max-age=86400, což je 24 hodin v sekundách). httplib2 hlavičkám pro mezipaměť rozumí a respektuje je. Předchozí odpověď byla uložena do adresáře .cache (jehož jméno jsme zadali při vytváření objektu třídy Http). Platnost obsahu mezipaměti zatím nevypršela, takže když data ze stejného URL požadujeme podruhé, httplib2 jednoduše vrátí zapamatovaný výsledek, aniž by došlo ke komunikaci po síti.
Říkám „jednoduše“, ale za touto jednoduchostí je evidentně skryto hodně složitostí. Knihovna httplib2 zvládá používání mezipaměti v HTTP automaticky a aniž se o to musíme starat. Pokud z nějakého důvodu potřebujeme vědět, zda odpověď přichází z mezipaměti, můžeme zkontrolovat response.fromcache. Z jiného pohledu… prostě to funguje.
Dejme tomu, že teď máme data v mezipaměti, ale chceme ji obejít a znovu si je vyžádat od vzdáleného serveru. Prohlížeče to někdy dělají, když si to uživatel vyžádá. Například stisk F5 obnoví aktuální stránku, ale stiskem Ctrl+F5 se obejde mezipaměť a aktuální stránka se znovu vyžádá ze vzdáleného serveru. Možná si myslíte „aha, prostě smažu data ze své lokální mezipaměti a provedu požadavek znovu“. Tohle byste udělat mohli. Ale vzpomeňte si, že se to může týkat více stran než jen vás a vzdáleného serveru. Což takhle mezilehlé proxy-servery? Ty jsou zcela mimo vaši kontrolu a pořád mohou uchovávat ona data ve své mezipaměti. A s radostí vám je vrátí, protože obsah jejich mezipaměti je (z jejich pohledu) stále platný.
Takže místo toho, abyste manipulovali s lokální mezipamětí a doufali v nejlepší, měli byste využít vlastností HTTP k zajištění toho, že se váš požadavek skutečně dostal až ke vzdálenému serveru.
# pokračování předchozího příkladu
>>> response2, content2 = h.request('http://diveintopython3.org/examples/feed.xml',
... headers={'cache-control':'no-cache'}) ①
connect: (diveintopython3.org, 80) ②
send: b'GET /examples/feed.xml HTTP/1.1
Host: diveintopython3.org
user-agent: Python-httplib2/$Rev: 259 $
accept-encoding: deflate, gzip
cache-control: no-cache'
reply: 'HTTP/1.1 200 OK'
…further debugging information omitted…
>>> response2.status
200
>>> response2.fromcache ③
False
>>> print(dict(response2.items())) ④
{'status': '200',
'content-length': '3070',
'content-location': 'http://diveintopython3.org/examples/feed.xml',
'accept-ranges': 'bytes',
'expires': 'Wed, 03 Jun 2009 00:40:26 GMT',
'vary': 'Accept-Encoding',
'server': 'Apache',
'last-modified': 'Sun, 31 May 2009 22:51:11 GMT',
'connection': 'close',
'-content-encoding': 'gzip',
'etag': '"bfe-255ef5c0"',
'cache-control': 'max-age=86400',
'date': 'Tue, 02 Jun 2009 00:40:26 GMT',
'content-type': 'application/xml'}
httplib2 vám umožní přidat k jakémukoliv odcházejícímu požadavku libovolné HTTP hlavičky. Abychom obešli všechny mezipaměti (nejen lokální diskovou, ale také mezipaměťové proxy-servery mezi námi a vzdáleným serverem), přidáme do slovníku headers hlavičku no-cache.
httplib2 zahajuje síťový požadavek. httplib2 rozumí hlavičkám pro mezipaměť a respektuje je v obou směrech — jako součást přicházející odpovědi i jako součást odcházejícího požadavku. Knihovna si všimla, že jsme přidali hlavičku no-cache, takže úplně obešla své lokální mezipaměti. Potom ale nemá na výběr a musí odeslat požadavek na data do sítě.
httplib2 použije pro aktualizaci své lokální mezipaměti v naději, že se při příštím požadavku na stejná data bude moci vyhnout přístupu na síť. Návrh používání mezipamětí v HTTP je zcela podřízen maximalizaci úspěšnosti mezipamětí (cache hit) a minimalizaci přístupu k síti. I když jsme tentokrát mezipaměti obešli, vzdálený server by opravdu ocenil, kdybychom si výsledek do mezipaměti uložili — s ohledem na příští možný dotaz.
httplib2 zachází s hlavičkami Last-Modified a ETagHlavičky mezipaměti Cache-Control a Expires se nazývají indikátory čerstvosti (freshness indicators). Říkají mezipamětem jasným způsobem, že se do vypršení platnosti obsahu mezipaměti můžeme zcela vyhnout přístupu k síti. Přesně takové chování jsme viděli v předchozí podkapitole: pokud je indikována čerstvost, httplib2 při vrácení dat z mezipaměti negeneruje ani bajt síťové aktivity (pokud ovšem explicitně nepředepíšeme obejití mezipaměti).
Ale jak to bude vypadat v případě, kdy se data mohla změnit, ale přitom se nezměnila? Pro tento účel HTTP definuje hlavičky Last-Modified a Etag. Těmto hlavičkám se říká validátory. Pokud už lokální mezipaměť není čerstvá, může klient s dalším dotazem zaslat validátory, aby si ověřil, zda se data skutečně změnila. Pokud se data nezměnila, server pošle zpět stavový kód 304 a žádná data. Takže tu sice stále dochází ke vzájemné komunikaci po síti, ale výsledkem je stahování menšího množství bajtů.
>>> import httplib2
>>> httplib2.debuglevel = 1
>>> h = httplib2.Http('.cache')
>>> response, content = h.request('http://diveintopython3.org/') ①
connect: (diveintopython3.org, 80)
send: b'GET / HTTP/1.1
Host: diveintopython3.org
accept-encoding: deflate, gzip
user-agent: Python-httplib2/$Rev: 259 $'
reply: 'HTTP/1.1 200 OK'
>>> print(dict(response.items())) ②
{'-content-encoding': 'gzip',
'accept-ranges': 'bytes',
'connection': 'close',
'content-length': '6657',
'content-location': 'http://diveintopython3.org/',
'content-type': 'text/html',
'date': 'Tue, 02 Jun 2009 03:26:54 GMT',
'etag': '"7f806d-1a01-9fb97900"',
'last-modified': 'Tue, 02 Jun 2009 02:51:48 GMT',
'server': 'Apache',
'status': '200',
'vary': 'Accept-Encoding,User-Agent'}
>>> len(content) ③
6657
httplib2 s požadavkem nic moc udělat a odešle s ním minimum hlaviček.
ETag, tak hlavičku Last-Modified.
# pokračování z předchozího příkladu
>>> response, content = h.request('http://diveintopython3.org/') ①
connect: (diveintopython3.org, 80)
send: b'GET / HTTP/1.1
Host: diveintopython3.org
if-none-match: "7f806d-1a01-9fb97900" ②
if-modified-since: Tue, 02 Jun 2009 02:51:48 GMT ③
accept-encoding: deflate, gzip
user-agent: Python-httplib2/$Rev: 259 $'
reply: 'HTTP/1.1 304 Not Modified' ④
>>> response.fromcache ⑤
True
>>> response.status ⑥
200
>>> response.dict['status'] ⑦
'304'
>>> len(content) ⑧
6657
Http (a se stejnou lokální mezipamětí).
httplib2 pošle serveru zpět validátor ETag jako obsah hlavičky If-None-Match.
httplib2 pošle zpět serveru také validátor Last-Modified jako hodnotu hlavičky If-Modified-Since.
304 a žádná data.
httplib2 obdrží stavový kód 304 a načte obsah stránky ze své mezipaměti.
304 (který vrátil server teď a který způsobil, že httplib2 použije svou mezipaměť) a 200 (který vrátil server minule a který je spolu s daty uložen v mezipaměti pro httplib2). response.status vrací stavový kód odpovědi z mezipaměti.
response.dict, což je slovník aktuálních hlaviček vrácených serverem.
httplib2 je dost chytrá na to, abychom si mohli hrát na hlupáky.) V tomto okamžiku už metoda request() vrátila řízení volajícímu kódu. httplib2 už aktualizovala svou mezipaměť a vrátila nám data.
http2lib pracuje s kompresíHTTP podporuje několik typů komprese. Dva nejpoužívanější typy jsou gzip a deflate. httplib2 podporuje oba.
>>> response, content = h.request('http://diveintopython3.org/')
connect: (diveintopython3.org, 80)
send: b'GET / HTTP/1.1
Host: diveintopython3.org
accept-encoding: deflate, gzip ①
user-agent: Python-httplib2/$Rev: 259 $'
reply: 'HTTP/1.1 200 OK'
>>> print(dict(response.items()))
{'-content-encoding': 'gzip', ②
'accept-ranges': 'bytes',
'connection': 'close',
'content-length': '6657',
'content-location': 'http://diveintopython3.org/',
'content-type': 'text/html',
'date': 'Tue, 02 Jun 2009 03:26:54 GMT',
'etag': '"7f806d-1a01-9fb97900"',
'last-modified': 'Tue, 02 Jun 2009 02:51:48 GMT',
'server': 'Apache',
'status': '304',
'vary': 'Accept-Encoding,User-Agent'}
httplib2 odešle požadavek, vloží do něj hlavičku Accept-Encoding, kterou serveru oznámí, že zvládá jak kompresi deflate, tak gzip.
request() vrací řízení, httplib2 dekomprimovala (rozbalila) tělo odpovědi a umístila je do proměnné content. Pokud jste zvědaví, jestli odpověď přišla komprimovaná, můžete zkontrolovat response['-content-encoding']. Ale jinak si s tím nemusíte dělat starosti.
httplib2 řeší přesměrováníHTTP definuje dva druhy přesměrování: dočasné a trvalé. U dočasných přesměrování se nedělá nic zvláštního až na to, že se mají následovat (follow), což httplib2 provede automaticky.
>>> import httplib2
>>> httplib2.debuglevel = 1
>>> h = httplib2.Http('.cache')
>>> response, content = h.request('http://diveintopython3.org/examples/feed-302.xml') ①
connect: (diveintopython3.org, 80)
send: b'GET /examples/feed-302.xml HTTP/1.1 ②
Host: diveintopython3.org
accept-encoding: deflate, gzip
user-agent: Python-httplib2/$Rev: 259 $'
reply: 'HTTP/1.1 302 Found' ③
send: b'GET /examples/feed.xml HTTP/1.1 ④
Host: diveintopython3.org
accept-encoding: deflate, gzip
user-agent: Python-httplib2/$Rev: 259 $'
reply: 'HTTP/1.1 200 OK'
302 Found. I když se to zde nezobrazuje, odpověď obsahuje také hlavičku Location, která ukazuje na skutečné URL.
httplib2 se ihned otočí a „následuje“ přesměrování vydáním dalšího požadavku na URL, které je uvedeno v hlavičce Location: http://diveintopython3.org/examples/feed.xml
„Následování“ přesměrování není nic jiného, než co ukazuje tento příklad. httplib2 pošle požadavek pro URL, které jsme požadovali. Server odvětí odpovědí, která říká: „Ne ne. Místo toho se podívejte támhle.“ httplib2 odešle další požadavek pro nové URL.
# pokračování z předchozího příkladu >>> response ① {'status': '200', 'content-length': '3070', 'content-location': 'http://diveintopython3.org/examples/feed.xml', ② 'accept-ranges': 'bytes', 'expires': 'Thu, 04 Jun 2009 02:21:41 GMT', 'vary': 'Accept-Encoding', 'server': 'Apache', 'last-modified': 'Wed, 03 Jun 2009 02:20:15 GMT', 'connection': 'close', '-content-encoding': 'gzip', ③ 'etag': '"bfe-4cbbf5c0"', 'cache-control': 'max-age=86400', ④ 'date': 'Wed, 03 Jun 2009 02:21:41 GMT', 'content-type': 'application/xml'}
request(), je odpovědí z konečného URL.
httplib2 přidá konečné URL do slovníku response jako content-location. Nejde o hlavičku, která by přišla ze serveru. Je to záležitost specifická pro httplib2.
Slovník response, který se nám vrátí, poskytuje informace o konečném URL. A co když chceme informace o přechodných URL, tedy o těch, která byla přesměrována na konečné URL? httplib2 nám umožní i to.
# pokračování z předchozího příkladu >>> response.previous ① {'status': '302', 'content-length': '228', 'content-location': 'http://diveintopython3.org/examples/feed-302.xml', 'expires': 'Thu, 04 Jun 2009 02:21:41 GMT', 'server': 'Apache', 'connection': 'close', 'location': 'http://diveintopython3.org/examples/feed.xml', 'cache-control': 'max-age=86400', 'date': 'Wed, 03 Jun 2009 02:21:41 GMT', 'content-type': 'text/html; charset=iso-8859-1'} >>> type(response) ② <class 'httplib2.Response'> >>> type(response.previous) <class 'httplib2.Response'> >>> response.previous.previous ③ >>>
httplib2 následovala, aby získala současný objekt odpovědi.
httplib2.Response.
None.
Co se stane, když si vyžádáme stejné URL znovu?
# pokračování z předchozího příkladu
>>> response2, content2 = h.request('http://diveintopython3.org/examples/feed-302.xml') ①
connect: (diveintopython3.org, 80)
send: b'GET /examples/feed-302.xml HTTP/1.1 ②
Host: diveintopython3.org
accept-encoding: deflate, gzip
user-agent: Python-httplib2/$Rev: 259 $'
reply: 'HTTP/1.1 302 Found' ③
>>> content2 == content ④
True
httplib2.Http (a tím pádem stejná mezipaměť).
302 nebyla v mezipaměti, takže httplib2 pošle pro stejné URL další požadavek.
302. Ale všimněte si, co se nestalo: chybí druhý dotaz na konečné URL, http://diveintopython3.org/examples/feed.xml. Tato odpověď byla v mezipaměti (vzpomeňte si na hlavičku Cache-Control, kterou jsme viděli v předchozím příkladu). Jakmile httplib2 obdržela kód 302 Found, zkontrolovala si před vydáním dalšího požadavku obsah mezipaměti. Mezipaměť obsahovala čerstvou kopii http://diveintopython3.org/examples/feed.xml, takže nebylo nutné žádat o data znovu.
request(). Přečetla data publikovaného obsahu (feed) z mezipaměti a vrátila je. Jde samozřejmě o stejná data, která jsme obdrželi minule.
Jinými slovy, při dočasném přesměrování nemusíme dělat nic zvláštního. httplib2 je bude následovat automaticky. Skutečnost, že je jedno URL přesměrováno na jiné, nemá na httplib2 žádné dopady z hlediska podpory komprese, použití mezipaměti, ETagů nebo jakýchkoliv jiných rysů HTTP.
Trvalá přesměrování jsou stejně jednoduchá.
# pokračování z předchozího příkladu
>>> response, content = h.request('http://diveintopython3.org/examples/feed-301.xml') ①
connect: (diveintopython3.org, 80)
send: b'GET /examples/feed-301.xml HTTP/1.1
Host: diveintopython3.org
accept-encoding: deflate, gzip
user-agent: Python-httplib2/$Rev: 259 $'
reply: 'HTTP/1.1 301 Moved Permanently' ②
>>> response.fromcache ③
True
http://diveintopython3.org/examples/feed.xml.
301. Ale znovu si všimněte, co se nestalo: neobjevil se žádný požadavek na přesměrované URL. Proč ne? Protože už se nachází v lokální mezipaměti.
httplib2 „následovala“ přesměrování přímo do své mezipaměti.
Ale počkejte! Ono je toho ještě víc!
# pokračování z předchozího příkladu
>>> response2, content2 = h.request('http://diveintopython3.org/examples/feed-301.xml') ①
>>> response2.fromcache ②
True
>>> content2 == content ③
True
httplib2 následuje trvalé přesměrování, všechny další požadavky se stejným URL budou transparentně přepsány na cílové URL aniž se kvůli originálnímu URL komunikuje po síti. Připomeňme si, že ladicí režim je pořád zapnutý. Přesto nevidíme vůbec žádný výstup síťové aktivity.
HTTP. Funguje.
⁂
Webové služby nad HTTP se neomezují jen na požadavky typu GET. Co kdybychom chtěli vytvořit něco nového? Kdykoliv přidáte komentář do diskusního fóra, aktualizujete weblog, upravujete svůj stav na mikroblogové službě, jakou je Twitter nebo Identi.ca, používáte pravděpodobně HTTP POST.
Jak Twitter, tak Identi.ca nabízejí pro zveřejňování a aktualizaci vašeho stavu, popsaného 140 nebo méně znaky, jednoduché rozhraní založené na HTTP. Podívejme se na dokumentaci aplikačního rozhraní pro aktualizaci vašeho stavu v systému Identi.ca.
Identi.ca REST API Metoda: statuses/update
Aktualizuje stav autentizovaného uživatele. Vyžaduje parametrstatus, popsaný níže. Požadavek musí být typuPOST.
- URL
https://identi.ca/api/statuses/update.format- Formáty
xml,json,rss,atom- HTTP metod(y)
POST- Vyžaduje autentizaci
- ano
- Parametry
status. Povinný. Text aktualizace vašeho stavu. Kódované URL podle potřeby.
Jak to funguje? Když chceme na Identi.ca zveřejnit novou zprávu, musíme zaslat požadavek typu HTTP POST na http://identi.ca/api/statuses/update.format. (Část format nepatří k URL. Nahrazuje se datovým formátem, v jakém nám má server vrátit odpověď na náš požadavek. Takže pokud požadujeme odpověď v XML, musíme zaslat požadavek na https://identi.ca/api/statuses/update.xml.) Požadavek musí obsahovat parametr nazvaný status, který obsahuje text pro aktualizaci našeho stavu. A požadavek musí být autentizován.
Autentizován? Jistě. Když chceme na Identi.ca aktualizovat svůj stav, musíme prokázat svou totožnost. Identi.ca není jako wiki. Svůj vlastní stav můžeme aktualizovat jen my. Pro účel bezpečné a snadno použitelné autentizace používá Identi.ca HTTP Basic Authentication (základní autentizaci; známou také jako RFC 2617) přes SSL. httplib2 podporuje jak SSL, tak HTTP Basic Authentication, takže tahle část bude snadná.
Požadavek POST se od požadavku GET liší, protože nese náklad. Nákladem jsou data, která chceme poslat na server. Částí dat, kterou toto aplikační rozhraní metody vyžaduje, je status (stav) a měl by mít podobu kódovaného URL. Je to velmi jednoduchý serializační formát. Vstupem je množina dvojic klíč-hodnota (tj. slovník) a výsledkem je řetězec.
>>> from urllib.parse import urlencode ① >>> data = {'status': 'Test update from Python 3'} ② >>> urlencode(data) ③ 'status=Test+update+from+Python+3'
urllib.parse.urlencode().
status, jehož hodnotou je text jedné aktualizace stavu.
POST odeslán „po drátě“ na server s aplikačním rozhraním Identi.ca.
>>> from urllib.parse import urlencode
>>> import httplib2
>>> httplib2.debuglevel = 1
>>> h = httplib2.Http('.cache')
>>> data = {'status': 'Test update from Python 3'}
>>> h.add_credentials('diveintomark', 'MY_SECRET_PASSWORD', 'identi.ca') ①
>>> resp, content = h.request('https://identi.ca/api/statuses/update.xml',
... 'POST', ②
... urlencode(data), ③
... headers={'Content-Type': 'application/x-www-form-urlencoded'}) ④
httplib2 pracuje s autentizací. Jméno a heslo uložíme metodou add_credentials(). Když se httplib2 pokusí o vydání požadavku, server odpoví stavovým kódem 401 Unauthorized (neautorizováno) a připojí seznam autentizačních metod, které podporuje (v hlavičce WWW-Authenticate). httplib2 automaticky vytvoří hlavičku Authorization a pošle požadavek s URL znovu.
POST.
☞Třetím parametrem metody
add_credentials()je doména, ve které osobní údaje platí. Měli byste ji vždy uvádět! Pokud doménu vynecháte a později znovu použijete objekt třídyhttplib2.Httppro jiné autentizované místo, mohla byhttplib2způsobit únik jména a hesla z jednoho místa na druhé místo (site).
A o čem zpívají dráty:
# pokračování z předchozího příkladu send: b'POST /api/statuses/update.xml HTTP/1.1 Host: identi.ca Accept-Encoding: identity Content-Length: 32 content-type: application/x-www-form-urlencoded user-agent: Python-httplib2/$Rev: 259 $ status=Test+update+from+Python+3' reply: 'HTTP/1.1 401 Unauthorized' ① send: b'POST /api/statuses/update.xml HTTP/1.1 ② Host: identi.ca Accept-Encoding: identity Content-Length: 32 content-type: application/x-www-form-urlencoded authorization: Basic SECRET_HASH_CONSTRUCTED_BY_HTTPLIB2 ③ user-agent: Python-httplib2/$Rev: 259 $ status=Test+update+from+Python+3' reply: 'HTTP/1.1 200 OK' ④
401 Unauthorized. httplib2 nikdy neposílá autentizační hlavičky, pokud si o ně server explicitně neřekne. Server si o ně říká tímto způsobem.
httplib2 okamžitě zareaguje opakovaným odesláním požadavku se stejným URL.
add_credentials().
A co vlastně server posílá po úspěšném požadavku zpět? To zcela závisí na aplikačním rozhraní příslušné webové služby. V některých protokolech (jako například Atom Publishing Protocol) posílá server zpět stavový kód 201 Created spolu s umístěním nově vytvořeného zdroje (resource) v hlavičce Location. Identi.ca posílá zpět 200 OK a XML dokument, který obsahuje informace o nově vytvořeném zdroji.
# pokračování z předchozího příkladu
>>> print(content.decode('utf-8')) ①
<?xml version="1.0" encoding="UTF-8"?>
<status>
<text>Test update from Python 3</text> ②
<truncated>false</truncated>
<created_at>Wed Jun 10 03:53:46 +0000 2009</created_at>
<in_reply_to_status_id></in_reply_to_status_id>
<source>api</source>
<id>5131472</id> ③
<in_reply_to_user_id></in_reply_to_user_id>
<in_reply_to_screen_name></in_reply_to_screen_name>
<favorited>false</favorited>
<user>
<id>3212</id>
<name>Mark Pilgrim</name>
<screen_name>diveintomark</screen_name>
<location>27502, US</location>
<description>tech writer, husband, father</description>
<profile_image_url>http://avatar.identi.ca/3212-48-20081216000626.png</profile_image_url>
<url>http://diveintomark.org/</url>
<protected>false</protected>
<followers_count>329</followers_count>
<profile_background_color></profile_background_color>
<profile_text_color></profile_text_color>
<profile_link_color></profile_link_color>
<profile_sidebar_fill_color></profile_sidebar_fill_color>
<profile_sidebar_border_color></profile_sidebar_border_color>
<friends_count>2</friends_count>
<created_at>Wed Jul 02 22:03:58 +0000 2008</created_at>
<favourites_count>30768</favourites_count>
<utc_offset>0</utc_offset>
<time_zone>UTC</time_zone>
<profile_background_image_url></profile_background_image_url>
<profile_background_tile>false</profile_background_tile>
<statuses_count>122</statuses_count>
<following>false</following>
<notifications>false</notifications>
</user>
</status>
httplib2 jsou vždy bajty a ne řetězce. Abychom je mohli převést na řetězec, musíme je dekódovat s použitím příslušného znakového kódování. Aplikační rozhraní systému Identi.ca vždy vrací výsledky v UTF-8. Takže tato část je snadná.
A tady ji máme:
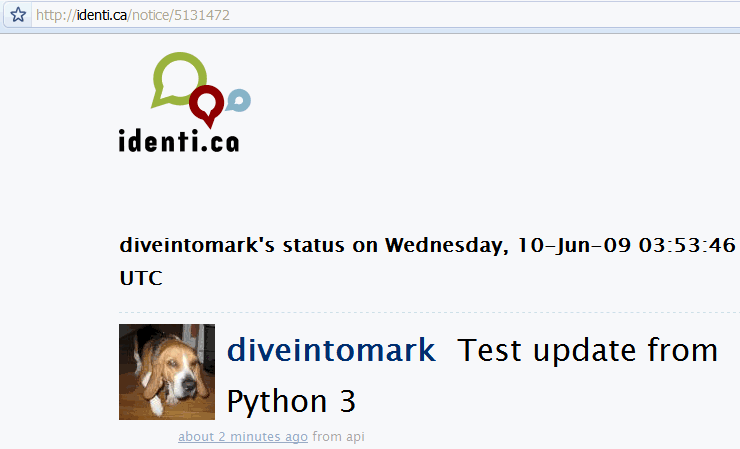
⁂
HTTP se neomezuje jen na GET a POST. Nepochybně jde o nejběžnější typy dotazů, obzvlášť ze strany webových prohlížečů. Ale rozhraní webových služeb může jít za hranice GET a POST — a knihovna httplib2 je na to připravená.
# pokračování z předchozího příkladu >>> from xml.etree import ElementTree as etree >>> tree = etree.fromstring(content) ① >>> status_id = tree.findtext('id') ② >>> status_id '5131472' >>> url = 'https://identi.ca/api/statuses/destroy/{0}.xml'.format(status_id) ③ >>> resp, deleted_content = h.request(url, 'DELETE') ④
findtext() najde první objekt odpovídající zadanému výrazu a extrahuje jeho textový obsah. V tomto případě hledáme element <id>.
<id> můžeme zkonstruovat URL pro vymazání stavové zprávy, kterou jsme zrovna zveřejnili.
DELETE.
Po drátech běhá následující:
send: b'DELETE /api/statuses/destroy/5131472.xml HTTP/1.1 ① Host: identi.ca Accept-Encoding: identity user-agent: Python-httplib2/$Rev: 259 $ ' reply: 'HTTP/1.1 401 Unauthorized' ② send: b'DELETE /api/statuses/destroy/5131472.xml HTTP/1.1 ③ Host: identi.ca Accept-Encoding: identity authorization: Basic SECRET_HASH_CONSTRUCTED_BY_HTTPLIB2 ④ user-agent: Python-httplib2/$Rev: 259 $ ' reply: 'HTTP/1.1 200 OK' ⑤ >>> resp.status 200
Puf a je to pryč.
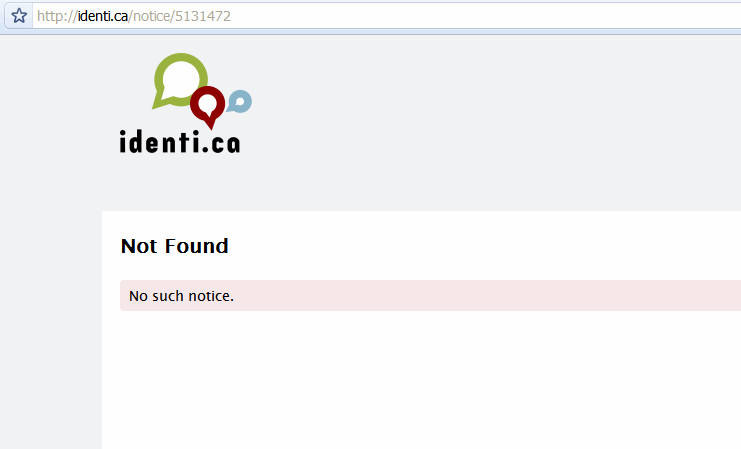
⁂
httplib2:
httplib2 (anglicky)
httplib2 (anglicky)
httplib2 (anglický článek)
httplib2: HTTP Persistence and Authentication (anglický článek)
Práce HTTP s mezipamětí:
RFC:
© 2001–11 Mark Pilgrim